









この記事は約 9 分で読めます。

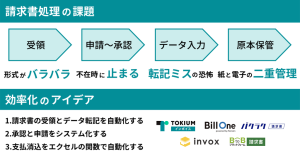
経理の時間を奪うのは、伝票そのものより明細“行”の入力です。取引先ごとに様式が異なり、1枚で数十〜百行になるケースも珍しくありません。近年はAI-OCRやカード明細の自動取込に加え、明細行まで読み取り・入力を担うAIエージェントが登場し、人的チェックの負担を大きく減らせる段階に来ました。
本稿では、明細入力をAIで自動化する要点と手順、法対応、効果を最大化する運用設計を、具体例と失敗しないコツまで含めて解説します。最新動向もあわせて整理します。
AIを導入する前に明細入力の「壁」を特定する
明細入力は、同じ“請求書処理”でも負荷の大半を占めます。取引先ごとに列見出しや行構成が違い、AI-OCRだけでは定型化しにくい点が「壁」でした。最新トレンドでは、OCRに加えて文脈を理解して行を構造化するAIや、カード明細の自動取込が普及。さらに明細行→仕訳まで一気に自動入力する動きが強まっています。
AI-OCR連携による自動化の限界
これまでの自動化は、紙やPDFの内容を文字として読取り、システムに取り込むところまでが中心でした。合計金額や日付、発行元などの基本情報は一定の精度で抽出できますが、明細“行”まで正確に区切って意味づけするのは難しく、取引先ごとに表の形が違うと設定や手直しが増えがちでした。会計システムとの連携で入力の手間は減るものの、列のズレや単位の違い、税区分の判断などで確認作業が残ります。結果として、人が行うチェックと修正がボトルネックとなり、処理量が多い月末月初ほど滞留が発生していました。
行まで読むAIでカード明細の“手入力ゼロ化”を実現
近年は、文字を読むだけでなく表の構造を理解し、項目の意味を推測して並べ直すAIが登場しています。たとえば、品目名や数量、単価、税区分といった列を自動で見つけて、欠けた値を補ったり、表記ゆれをそろえたりできます。これにより、明細“行”の単位でデータ化でき、後工程の仕訳作成まで一体で進めやすくなりました。あわせて、カードの利用明細を自動で取り込み、申請や照合に必要な情報を紐づける仕組みが広がったため、小口の立替や定期支払いは手入力の場面がほぼなくなります。現場は“入力”より“確認”に集中でき、処理のばらつきが小さくなります。

どこまでAIで明細入力を自動化できる?
AIでの自動化範囲は「領収書→基本項目」「請求書→明細行」「カード→利用明細」と段階的に広がります。最新では請求書・納品書・発注書の明細行を読み取り、仕訳案の入力まで担う例が出ています。本章では対象書類別の到達点と、人の確認を残すポイントを整理します。
領収書:金額・日付・店名の自動読取の現実値
領収書の自動化は、金額・日付・発行元といった基本項目で最も効果が出やすい領域です。文字が薄い、手書き、感熱紙の劣化など読みにくい条件でも、複数の候補から最有力を示す仕組みを組み合わせることで、確認の負担を大幅に減らせます。一方で、支払理由や社内規程に照らした可否判断など、文脈理解を伴う部分は人の最終判断を残すのが実務的です。レシートの行情報は、項目名や単位の表記が多様なため、読み取り後に部門や用途の区分へ自動で振り分けるルールを整えると、社内精算のスピードが一段と上がります。
請求書・納品書・発注書:明細“行”の構造化と精度
請求書や納品書は、行の粒度で正しく分割し、品目、数量、単価、金額、税区分、備考などを列としてそろえることが要になります。最新のAIは、表の罫線が不明瞭でも、周囲の文字配置から列を推定し、見出し語の違い(例:「品名」「商品名」)を同義として扱えます。また、合計値と行の小計の突合により、誤検知を洗い出す自己点検も行えます。とはいえ、品目の細かい分類や社内の費用科目への当てはめは、初期は間違いが生じやすい部分です。修正履歴を学習に反映し、頻出パターンから優先的に精度を上げる運用が効果的です。
カード明細:自動連携で申請・照合を軽くする
カード明細は、利用日時、加盟店名、金額が整った形でデータ化できるため、取り込みさえ自動化できれば申請や照合の負担が一気に下がります。店名の表記ゆれや海外利用の通貨換算、複数回に分かれた請求など、実務でよくある例外は残りますが、ルール化しやすいものが多く、差戻しの主因を早期に減らせます。領収書の画像と明細の突合を自動で提示する仕組みを使えば、承認者は“判断が必要なケース”から優先して確認できます。定期利用のサブスクリプション費用などは自動仕訳の候補が安定しやすく、月次の締めも前倒しできます。
カード明細は“整ったデータ”ですが、レシート画像との突合や海外利用の換算、分割請求などの例外で詰まりやすくなります。運用では、明細取込→画像突合→差異しきい値判定→承認の順に自動化し、しきい値を超える差異だけ人が見る流れにします。定期支払いは事前登録で科目・部門を固定し、例外発生時のみ通知します。外部の一般解説でもカード連携の効率化は広く認められており、社内の負担軽減に直結しますが、差異しきい値と通知条件の設計が成否を分けます。
仕訳までの自動入力:どこに人が関与するか
仕訳の自動入力では、品目や取引の内容から勘定科目・税区分・部門を候補として提示し、確定した結果を学習に戻す循環が要です。初期は“科目の候補が複数ある”“部門の判断基準が曖昧”など迷いやすい場面が生じます。ここは、金額や取引先、契約種別などの条件で「人が確認する範囲」を明確にしておくと、過剰なチェックを避けつつリスクを抑えられます。迷いがちな案件は上長への引き上げ基準を言語化し、履歴を残します。学習が進むと候補の精度が上がるため、人の関与は“例外”と“最終承認”に段階的に集約されます。
明細入力AIはスモールスタートから本格展開する
「スモールスタート」で対象帳票とチェック観点を絞り、1〜2か月で改善サイクルを回します。次に対象拠点・取引先の拡大、承認フローとの連携、上長への引き上げ基準などを整えて本格運用へ。ログ保存と差分レビューを設計し、ミスの再発を防ぎます。
対象選定:件数×行数×定型度で優先順位
まず、月次で件数が多く、1枚あたりの行数も多い帳票を洗い出します。次に、取引先ごとの書式のばらつきや、社内規程との照合が単純かどうかを見て、定型度の高い領域から取り組みます。たとえば、継続的に同じ形式で届く請求書や、明細の列が安定している納品書は、学習効果が早く表れます。逆に、季節要因で品目が大きく変わるものや、備考欄に判断材料が散在するものは、第二段階に回します。こうして「件数×行数×定型度」で優先順位を決めると、短期間で成果が見え、現場の理解と協力を得やすくなります。
スモールスタート:比較用の“人手基準”を先に決める
小さく始める段階では、対象帳票、処理フロー、確認観点を明確にし、現在の手作業時間や差戻し率を基準として記録しておきます。AIの読取結果に対し、どの修正が頻出か、どこで迷うのかを可視化することで、改善の焦点がはっきりします。検証期間は1~2か月を目安に、週次で気づきを反映します。ここで重要なのは、導入前後を公平に比べるための測定ルールを最初に合意しておくことです。基準が定まると、成功・失敗の判断がブレず、社内説明も進めやすくなります。小さな成功を積み重ねて、対象の拡大に備えます。
本格展開:承認・記録とつながる“回る仕組み”
本格展開では、読取→確認→承認→会計記録の一連の流れを分断せず、途中で生じる修正が次回に活きるよう仕組み化します。具体的には、修正理由を選択式で残し、誰が何を直したかを追えるようにします。承認経路は金額や取引種別で自動選択し、例外のみ上長へ引き上げる運用にすると滞留が減ります。さらに、明細データと証憑画像、仕訳の紐づけを整えておくと、監査対応もスムーズです。月次の締め前には読取を夜間に集中的に走らせ、日中は例外処理に集中することで、全体の処理時間を安定させられます。
上長への引き上げ/差し戻しのルール化
判断が分かれやすいケースを事前に定義し、金額や取引先、契約期間、備考のキーワードなど、具体的な条件で上長に引き上げる基準を作ります。同時に、差し戻し時は“どこが不十分か”を明確に伝える定型メッセージを用意し、再申請までの手戻りを減らします。基準は導入初期の実績をもとに定期的に見直し、不要な確認を減らしていきます。グレーな案件を「例外キュー」に集約し、対応後の結果を学習に返す流れを徹底すると、時間のかかる迷いが次第に減り、確認の質も均一になります。
例外は、金額差異、税区分の解釈違い、同一請求内の複数拠点按分、海外の通貨換算、店名の表記ゆれなど、発生源が決まっています。最初に“例外キュー”を作り、条件(差額%・自信度閾値・特定勘定など)に合致したら自動で集約し、上長への引き上げ基準を明文化します。差戻し時は“どこが不足か”を定型文で返し、再申請に必要な添付や記載を明確にします。
毎月、例外の上位パターンを3つだけ潰すサイクルを回すと、差戻し率が着実に下がります。併せて、取引先への依頼文例(品名表記の統一・税区分の明記など)を用意すると、例外の発生自体が減り、学習効果が高まりやすくなります。
明細入力AIの精度と品質管理方法
AIは修正履歴から学習し精度が上がります。だからこそ修正ログの粒度、再学習の間隔、サンプルの偏りの管理が要です。ダブルチェックが要る帳票や金額差異のしきい値を設け、夜間バッチでの集中読取と日中の例外処理を分離して安定化します。
学習の設計:修正ログ→再学習→検証の回し方
学習を機能させるには、修正の内容を“どの項目を、なぜ直したか”の単位で記録し、再学習に取り込む設計が欠かせません。再学習の頻度は、処理量が多い期間に偏らないよう、月次や四半期で定期化します。学習後は、過去データと新規データを混ぜた検証用セットで精度を測り、特定の取引先や品目に偏った改善になっていないかを確認します。改善効果が小さい場合は、見出し語の統一や単位換算の前処理など、学習前の整形を見直します。現場の修正がそのまま知見になる循環を作ることで、使うほど精度が上がっていきます。
以下のページでは、経理を明細入力“作業”から解放するステップを動画で確認できます。
例外の扱い:しきい値/上長への引き上げの基準
例外の扱いは、金額や差異の大きさ、読取の自信度など、定量的なしきい値を先に決めておくと混乱がありません。たとえば、合計と行の小計の差が一定以上なら必ず人が確認する、読取の自信度が低い項目は候補を提示して上長に引き上げる、などです。しきい値は厳しすぎても緩すぎても非効率になるため、導入初期のデータを見ながら段階的に調整します。頻出する例外は原因別に分類し、取引先への依頼文例や社内の記載ルールを整えると、例外自体が減っていきます。
ボトルネックの可視化:件数×行数×滞留時間の見える化
処理の遅れを早期に察知するには、帳票の件数だけでなく、1枚あたりの行数と、各工程の滞留時間を合わせて可視化します。行数が多い帳票が承認前で止まりがちなのか、読取後の修正で時間がかかっているのかを分けて見れば、改善の手を打つ順番が定まります。
ダッシュボードでは、前週比・前月比での推移や、上長への引き上げ件数の推移も示すと、基準の見直しや人員配置に活かせます。ボトルネックを共通認識にすることで、現場の優先順位が一致し、全体の処理時間が短縮します。

行→仕訳の精度を上げる明細入力AIの“修正ログ設計”
明細の“行”から仕訳までを安定させるには、AIそのものよりも修正ログの設計が要となります。どの項目を、なぜ直したのかを後から追える形で残し、定期的な見直しと学習へつなぐことで、使うほど精度が上がる循環が生まれます。本章では、ログの粒度、学習と検証の回し方、偏りの防ぎ方、差異検知と上長への引き上げ基準づくりを、現場で運用しやすい手順に落とし込みます。
ログの“粒度”を決める:項目単位+理由タグで再現可能に
修正ログは「誰が・いつ・どの項目を・どう直したか」だけでなく、“なぜ直したか”の理由まで残すと価値が高まります。たとえば「税区分の誤り」「数量の桁ずれ」「科目選択の判断変更」など、理由タグをプルダウンで選ばせると、集計と学習が容易です。行IDと証憑画像の対応(ページ・座標)も保持し、後からその行を正確に再現できるようにします。
ログは項目単位で残し、合計と行の小計の整合チェック結果もセットで保存。こうして“どこでズレたか”が即座に見えるようにしておくと、学習にも監査にも効きます。入力者の自由記述欄は最小限にし、理由タグ中心にするほど、ブレずにデータが貯まります。
学習と検証の回し方:月次の定期化と“公平な土俵”づくり
精度向上は定期的な学習サイクルが前提です。運用では、月次(または四半期)で「学習→検証→適用」を固定スケジュール化し、締め作業と重ならない時期に回します。検証は“公平な土俵”が大切です。過去月と当月のデータを混ぜ、取引先・業態・拠点で検証セットを用意すると、特定のパターンだけ良くなる偏りを見抜けます。
評価指標は、行ごとの正解率に加え、差戻し率/上長引き上げ率/夜間処理成功率など運用指標も併記すると、実務の改善度が伝わります。結果はダッシュボードで共有し、次の学習に反映する“打ち手”を週次で決めると、改善が止まりません。
偏りを防ぐ設計:頻出取引先とレアケースを分けて見る
学習は、件数の多い取引先や一定の品目に“効きがち”です。そこで、頻出パターンとレアケースを意図的に分けて評価します。頻出は短期での効果を狙い、レアは保守的な運用(人の確認を残す)で安全側に倒します。表記ゆれ(品名の別称、全角半角、英数混在)は、前処理辞書を用意して揺れを抑えると、学習の無駄が減ります。
また、為替や複数拠点按分など、計算を伴う項目は自動計算ルールを先に設計し、AIは計算ではなく“識別”に集中させます。こうして“AIが得意なところは任せ、人が判断すべきところは残す”線引きを明確にすると、全体の品質が安定します。
以下の記事では、A経理AIエージェントの活用シーンや導入ステップをについて詳しく解説しているので参考にしてください。

差異の自動検知と“上長への引き上げ”基準:迷う前に仕分ける
合計と行の小計の差、税区分の不一致、仕訳候補の自信度が低いケースなどは、差異のしきい値を設けて自動で振り分けます。しきい値を超えたものは“例外キュー”に集約し、上長への引き上げ基準(金額帯、取引種別、契約の有無、特定の勘定など)を明文化しておきます。
差し戻しの際は、定型メッセージで不足情報を明示し、再申請に必要な添付・記載を揃えてもらうと手戻りが減ります。週次で例外の上位3原因を潰す“定例改善”を回せば、引き上げ比率と差戻し率が徐々に下がり、人が見るべき案件に集中できる体制になります。結果として、締めの遅延も起きにくくなります。


明細入力AIの法対応と監査に耐える運用法
電帳法とインボイス制度の要件を満たすには、原本の真正性確保、検索性、改ざん防止と保存期間の管理が鍵です。AIを使っても保存と検索の要件は変わらないため、証憑・明細・承認のひも付けと修正履歴の保全を運用に組み込みます。
保存と検索要件:現場が迷わない“ひも付け”設計
電帳法とインボイス制度に対応するには、証憑画像、明細データ、承認記録、仕訳のそれぞれが相互にたどれる状態を保つことが大切です。検索では、取引先名、金額、日付、税区分など複数条件で即座に探せるようにし、後から修正した場合の履歴も残します。
ファイル名やタグの付け方を定め、申請者・承認者とも混乱しない運用ルールを整えると、監査や税務調査の対応がスムーズになります。迷いを減らす設計は、日々の作業時間の短縮にも直結します。
以下の記事では、インボイス制度が経理業務に与える影響を詳しく解説しているので参考にしてください。

改ざん防止・保存期間:システム設定の落とし穴
改ざん防止では、アップロード後の差し替えや削除に制限を設け、変更は履歴として残るようにします。タイムスタンプやハッシュ値の管理、権限設定の粒度など、初期設定を誤ると後から直すのが難しいため、導入時に必ず点検します。
保存期間は制度に合わせ、満了前の確認や保管場所の移行手順を決めておくと安心です。運用の現場では、例外的な差し替えが必要になることもあるため、作業の理由と承認者を記録する欄を用意すると、トラブル時の説明が明確になります。
以下の記事では、電子帳簿保存法に対応した請求書の保存方法を解説しているので参考にしてください。

法要件は“保存できれば良い”ではなく、証憑・明細・承認・仕訳が相互にたどれる状態を保つことが重要です。下表のリンク設計と履歴保全を最初に決めておけば、監査時の説明が簡潔になり、日常運用でも迷いが減ります。
電帳法・インボイスの“ひも付け”実装表
| 対象 | 必須の“ひも付け” | 運用ポイント | 監査対応のコツ |
|---|---|---|---|
| 証憑画像 | 明細データ・申請ID・承認ID・仕訳ID | アップロード後は差替え制限、変更は履歴保存 | 閲覧権限を段階化、閲覧ログを自動保存 |
| 明細“行”データ | 画像内の座標/ページ、行ID | 合計⇔小計の自動突合、差異のしきい値設定 | 差異理由テンプレを用意し再発防止に反映 |
| 承認記録 | 申請ID・承認者・時刻・差戻し理由 | 金額/種別で経路自動選択、例外のみ上長へ | 差戻し率の推移を月次で可視化 |
| 仕訳 | 証憑画像・明細行・承認記録のリンク | 学習に修正結果を自動反映(項目単位) | 科目変更の履歴を監査向けに即出力 |
以下の記事では、AIで経費精算を自動化する運用設計から法対応までを詳しく解説しているので参考にしてください。

時間→金額換算で明細入力AIの効果を測定する
1明細行あたりの入力秒数×行数×月次件数で削減時間を算出し、人件費単価を掛けて金額化します。やり直し(差戻し)率と夜間読取の成功率も併せて見ることで、投資対効果(ROI)と運用安定度を同時に管理できます。
入力秒数/差戻し率/夜間成功率の指標セット
効果測定の土台は、1明細行あたりの入力秒数と差戻し率です。これに、夜間に自動処理した読取の成功率や、上長への引き上げ件数の推移を加えると、運用の安定度を定量的に把握できます。指標は月次で集計し、対象帳票や取引先ごとに分けて見ると、改善の焦点が絞れます。
数値が悪化した場合は、直近でフォーマットが変わっていないか、学習データが偏っていないかを確認します。指標をチームで共有し、改善サイクルに組み込むことが、長期的な生産性向上につながります。
人件費単価×削減時間=月次効果
現場で使いやすいのは、時間を金額に変換する簡易表です。たとえば、入力秒数を5秒短縮できれば、行数が1万行の月は約14時間の削減です。人件費単価を掛ければ月次の金額効果が一目でわかります。さらに、差戻し率の低下や上長への引き上げ件数の減少も加味すると、確認工程の負荷軽減まで含めた実力値が把握できます。この早見表を定例会で共有すれば、投資判断や人員計画の説明がしやすくなります。
「時間→金額」かんたん早見表
| 短縮秒数/行 | 月間行数 | 削減時間(h) | 人件費単価(円/h) | 月次効果(円) |
|---|---|---|---|---|
| 5秒 | 10,000 | 13.9 | 3,000 | 41,700 |
| 8秒 | 20,000 | 44.4 | 3,000 | 133,200 |
| 10秒 | 30,000 | 83.3 | 3,000 | 249,900 |
“行”単位で秒数を測ると効果がブレません。差戻し率の低下や夜間読取の成功率も合わせて追うと、運用安定度を含めた実力値が把握できます。
現場が喜ぶ“入力ゼロ体験”を増やすのが定着のコツ
定着には、現場が“楽になった”と実感する瞬間を増やすことが重要です。よく使う帳票や定期的に届く請求から対象を広げ、手入力が不要なケースを日常的に体験できるようにします。修正の手間が残る箇所は、入力補助の候補を見やすく提示し、ワンクリックで確定できる形に整えるとストレスが減ります。フィードバック窓口を設け、現場の声を学習やルールの更新に素早く反映させることで、使い続けるほど賢くなる循環が生まれ、運用が自然に根付きます。
明細入力AIの事例・ユースケース
請求書・納品書・発注書の明細行に対応し、修正から学習して精度が上がるタイプのAIや、行読取→仕訳案入力まで担う仕組みが登場しています。製造・商社/拠点が多い業態ほど効果が出やすいのが特徴です。最後に関連する活用例と発表情報を紹介します。
AIが明細の入力・仕訳案まで担う流れ
TOKIUMの解説ページでは、AIが明細行を読み取り、科目や税区分、部門の候補まで提示し、確認後に仕訳として登録する一連の流れを、実際の画面イメージとともに紹介しています。どのタイミングで人が判断し、どこから自動で進むのかが具体的にわかるため、導入後の運用イメージづくりに役立ちます。段階的な広げ方や、修正履歴を学習に生かすポイントも整理されています。AI明細入力の活用例については、以下のページをご参照ください。
TOKIUM AI明細入力の全体像
明細情報を自動で入力する「TOKIUM AI明細入力」の提供開始に関する発表では、対象となる帳票の種類、どこまで自動化されるか、導入時の進め方の考え方など、全体像を把握するのに有用な情報がまとまっています。実務で気になる精度や運用面の工夫にも触れており、社内説明資料の基礎としても活用できます。詳細は、以下のプレスリリースをご覧ください。

まとめ
明細入力の自動化は、AI-OCRやカード明細の連携を土台に、いまや明細“行”の読取→仕訳案入力へ進化しています。はじめはスモールスタートで対象帳票とチェック観点を絞り、修正ログで学習→精度検証を回しながら本格展開へ。電帳法・インボイスの保存・検索・改ざん防止の要件は変わらないため、証憑と明細、承認のひも付けと履歴保全を運用で担保しましょう。定量指標(入力秒数・差戻し率など)で時間→金額に落とし込み、現場の“入力ゼロ体験”を増やすほど、効果は継続的に積み上がります。
FAQ
明細入力をAIで自動化する際によくいただく疑問を、実務の視点で一問一答にまとめました。どこまで自動化できるのか、電帳法・インボイスをどう満たすか、修正ログ設計で精度を上げる方法、例外の扱い、効果の測り方(時間→金額換算)までを整理しています。導入前の不安解消と運用後の見直しにご活用ください。
Q1. AIで明細行まで読むと、電帳法やインボイスの要件は変わりますか?
A. 変わりません。保存・検索・改ざん防止・保存期間の各要件を運用で満たす必要があります。実務では、証憑・明細・承認・仕訳の“ひも付け”と、変更履歴の保全を先に設計すると監査対応が容易です。
Q2. 精度が上がるまでの運用はどう回しますか?
A. 修正ログを項目単位で残し、月次の再学習と検証で偏りを点検します。差異しきい値と上長への引き上げ基準を明文化しておくと、過剰な確認を避けながらリスクを抑えられます。
Q3. 投資対効果はどう示せばよいですか?
A. 短縮秒数/行×月間行数÷3600で削減時間に換算し、人件費単価を掛ければ月次効果が出ます。差戻し率の改善や夜間処理の成功率も合わせて見ると、運用安定度まで説明できます。